Mesurer & décider avec l’échelle de Likert — Deux modèles Excel prêts à l’emploi (téléchargeables)
L’échelle de Likert (1→5 ou 1→7) permet de mesurer la perception (clients, marketing, UX, service, formation, engagement). En la combinant avec un cadre Go/No-Go, on passe d’avis subjectifs à des décisions traçables (GO / WAIT / NO GO) via des poids, seuils et règles simples.
Deux modèles Excel prêts à l’emploi (téléchargeables) couvrent la mesure et la décision.
1) L’idée centrale
- Likert standardise la perception (accord/désaccord) sur une échelle courte.
- Un cadre Go/No-Go transforme ces mesures (et d’autres critères factuels) en décision avec des seuils explicites.
- Résultat : un langage commun entre métier, qualité, marketing, produit, ops.
2) Comment fonctionne Likert (généralisation)
- Échelle : 1..5 (ou 1..7 si vous voulez plus de finesse).
- Items positifs / inversés :
- Positif (plus haut = mieux) → normalisation
z=(x−min)/(max−min) - Inversé/“coût” (plus bas = mieux) →
z=(max−x)/(max−min)
- Positif (plus haut = mieux) → normalisation
- Indicateurs clés :
- Moyenne (1..5) — sentiment moyen.
- Top2-box — part des réponses 4–5 (ou 6–7 en 1..7) : “% satisfaits”.
- Dispersion — écart-type pour détecter les divergences.
3) Du score à la décision (Go/No-Go)
- Score pondéré (0..1) = somme(normalisé × poids) ÷ somme(poids actifs).
- Seuils typiques : GO ≥ 0,75 ; WAIT 0,60–0,74 ; sinon NO GO.
- Règle mixte (recommandée) : seuil global + plancher sur quelques items critiques (ex. “Sécurité”, “Attente”, “Traçabilité”).
4) Deux modèles Excel complémentaires
Mesurer (perception multi-contextes)
Likert_Satisfaction_Marketing_MultiContextes.xlsx — CSAT, marketing, UX, service, formation, engagement.
- Banque de 12 items par contexte (activables), saisie multi-répondants, Dashboard (moyenne, Top2-box, décision).
- Version Compat fournie si votre Excel ne supporte pas FILTER/CONCAT.
Décider (arbitrer & prioriser)
GoNoGo_Likert_PassePartout.xlsx — analyse multi-critères avec scénarios de poids, normalisation et seuils GO/WAIT/NO GO.
- Vue projet détaillée (poids, normalisation, dispersion) + synthèse portefeuille.
5) Seuils & bonnes pratiques par grands usages
- CSAT/Service : Top2 ≥ 75–80 % ; attention aux items Attente, Réclamations, Fiabilité.
- Marketing (pré-test) : Top2 ≥ 70 % sur Message, Intention d’agir ; moyenne ≥ 4,0.
- UX : Top2 ≥ 75 % sur Facilité, Tâches clés, Erreurs ; plancher 3,8/5.
- Formation : Top2 ≥ 80 % sur Applicabilité & Objectifs.
- Engagement : Top2 ≥ 70 % ; alerte si Reconnaissance < 60 %.
6) Playbook de mise en œuvre (pas à pas)
- Cadrer : contexte, segments, canaux, volumétrie cible (≥ 30 réponses/segment).
- Choisir/adapter les 12 items (banque fournie), marquer les items inversés si nécessaire.
- Collecter les réponses (menus déroulants), taguer Segment & Canal.
- Lire le Dashboard (moyenne, Top2, décision) et repérer 2–3 items faibles.
- Décider avec le modèle Go/No-Go : injecter 2–3 indicateurs clés (Top2, moyenne, dispersion) comme critères pondérés.
- Tracer les conditions WAIT (action, responsable, date) + re-mesure.
7) Gouvernance & qualité de données
- Définir des libellés stables de segments et canaux pour comparer dans le temps.
- Taguer version d’item (code + tag) pour retracer les évolutions.
- Contrôler les volumes (éviter d’interpréter < 30 réponses).
- Mixer perception et KPI objectifs (délais, bugs, taux de conversion, NPS si vous l’utilisez).
8) Échelle 1→7 : quand et comment
- Utile pour départager des alternatives très proches (p. ex. créations marketing).
- Règles rapides :
- Recode inversé :
x_rev = 8 − x - Normalisation :
z = (x − 1) / 6 - Top2-box : 6–7.
- Recode inversé :
Deux modèles Likert complémentaires pour décider et piloter : GoNoGo_Likert_PassePartout.xlsx & Likert_Satisfaction_Marketing_MultiContextes.xlsx
Ces deux fichiers forment un duo pratique :
- le premier aide à décider (GO / WAIT / NO GO) grâce à une analyse multi-critères sur échelle de Likert ;
- le second permet de mesurer et comparer la perception (CSAT, marketing, UX, service, formation, engagement) avec des indicateurs standards (moyenne, Top2-box).
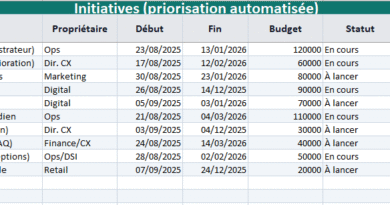
1) GoNoGo_Likert_PassePartout.xlsx — décider avec une Likert « universelle »
Prioriser et trancher rapidement entre plusieurs projets/initiatives, en combinant des notes Likert 1→5, une normalisation 0..1, des poids (jusqu’à 4 scénarios), et des seuils de décision.
Ce qu’il contient
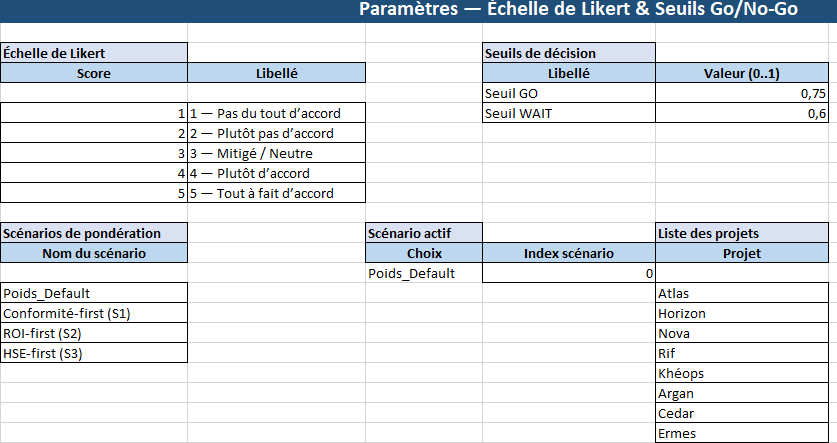
- Parametres_Likert : échelle Likert (libellés), seuils SEUIL_GO/SEUIL_WAIT, liste des projets, choix du scénario de poids (Default, Conformité-first, ROI-first, HSE-first).
- Questionnaire : 16 énoncés prêts à l’emploi (Stratégie, Économie, Technique & Données, Risque & Conformité, Ressources, Client/Qualité, HSE/Cyber, Gouvernance, Opérations) avec Sens (Positif/Inverse) et Poids (4 colonnes).
- Reponses (multi-évaluateurs) → Reponses_Num (conversion auto en 1..5).
- Agregat_Projet : pour un projet choisi → moyenne par item, normalisation (Bénéfice/Coût), poids effectif, écart-type (consensus), score global et décision (GO/WAIT/NO GO).
- Synthese_Projets : score global & décision pour tous les projets + graphique.
Comment ça décide (idée générale)
- Normalisation (0..1) par item :
- Positif :
(note − min) / (max − min) - Inversé/Coût :
(max − note) / (max − min)
- Positif :
- Score projet :
S = Σ (norme × poids) / Σ (poids actifs) - Règle : GO si
S ≥ SEUIL_GO, WAIT siSEUIL_WAIT ≤ S < SEUIL_GO, sinon NO GO.
Comités portefeuille, arbitrages entre alternatives, simulations de politique (changer de scénario de poids en un clic).

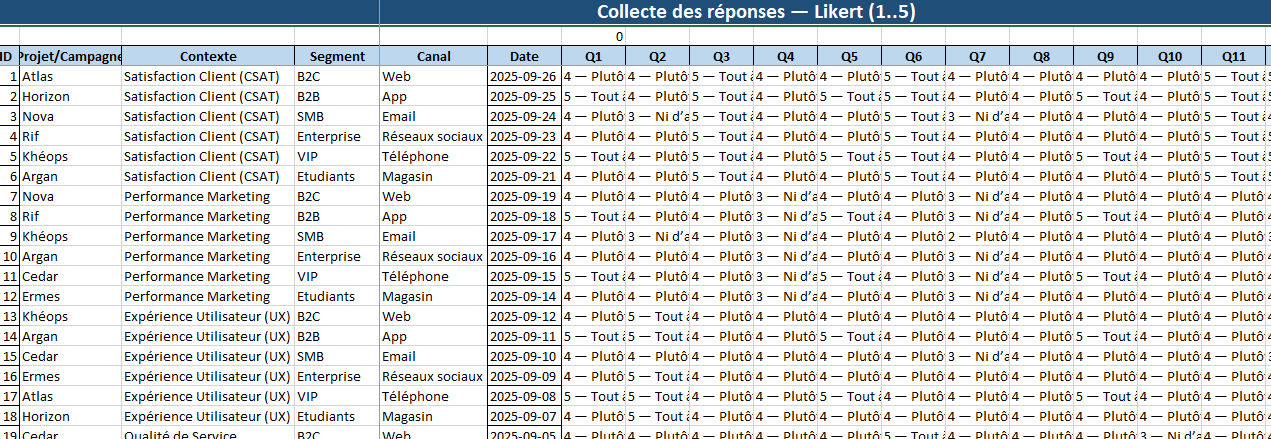
2) Likert_Satisfaction_Marketing_MultiContextes.xlsx — mesurer & comparer la perception
Mener des enquêtes rapides et comparables en CSAT, marketing, UX, qualité de service, formation, engagement avec une échelle Likert 1→5, des items prêts à l’emploi, et un Dashboard.
Ce qu’il contient
- Parametres : échelle, Top2-box cut (par défaut ≥ 4), Seuil de satisfaction (ex. 75 %).
- Banque_Items : 6 contextes × 12 items actifs (dimension, énoncé, poids, code, tags).
- Questionnaire : sélection du contexte → les 12 items se chargent (version complète) ; ou saisie manuelle (version Compat).
- Reponses / Reponses_Num : collecte multi-répondants (Projet/Campagne, Contexte, Segment, Canal, Date + Q1..Q12).
- Dashboard : moyenne par question, moyenne globale (1..5), % Top2-box moyen (part de réponses 4–5), décision (SATISFAIT / À AMÉLIORER) + 2 graphiques.
Comment ça décide (idée générale)
- Moyennes/Top2 par question :
AVERAGEIFS/COUNTIFSavec vos filtres (Contexte, Projet, Segment, Canal). - Top2-box moyen → comparer au Seuil de satisfaction (ex. 75 %).
- Option : exiger qu’aucun item critique ne soit sous un plancher (ex. < 60 % Top2).
Baromètres CSAT, pré-tests de campagne, suivi UX par écran/canal, qualité de service par site, évaluation « à chaud » de formation, baromètre d’engagement.
Erreurs fréquentes (et remèdes)
- #NOM? dans Excel → utilisez la version Compat (formules rétro-compatibles).
- #DIV/0! → aucun contexte/projet filtré : sélectionner B2 (contexte) et
*en E2 (tous les projets). - Biais d’acquiescement → alterner items positifs / inversés et surveiller la dispersion.
Mini-glossaire
- Likert : échelle d’accord/désaccord.
- Top2-box : part des réponses dans les deux niveaux supérieurs.
- Item inversé : formulation où une grande note = mauvaise performance (à re-coder).
- Go/No-Go : décision GO / WAIT / NO GO à partir d’un score pondéré et de seuils.

Passer de la mesure à l’impact : opérationnaliser Likert & Go/No-Go
On passe en mode exécution : comment industrialiser vos enquêtes Likert, relier les résultats au pilotage et garantir des décisions utiles (GO / WAIT / NO GO) avec un circuit d’actions clair.
1) Modèle opératoire (cadre en 5 rituels)
- Collecte (hebdo/mensuelle)
- Échantillons cibles par contexte × segment × canal (≥ 30 réponses).
- Questions stables, versions tracées.
- Consolidation (auto, dans le fichier)
- Moyenne (1..5), % Top-2 (4–5), dispersion.
- Filtres : Contexte, Projet, Segment, Canal.
- Lecture & alerte (hebdo)
- “Heatmap” des items faibles (< 60–70 % Top-2).
- Règle mixte : Top-2 global ≥ seuil ET aucun item critique sous plancher.
- Décision (comité bi-mensuel)
- Go/NoGo_Likert_PassePartout.xlsx : 3–5 critères alimentés par la mesure (ex. Top-2 global, Top-2 item critique, écart-type, impact ROI).
- Sortie : GO, WAIT (conditions/jalons), NO GO.
- Boucle d’action (suivi hebdo)
- Plan d’actions par item faible : action → owner → date → KPI attendu.
- Re-mesure ciblée après correction.
2) Cartographie “symptôme → diagnostic → actions”
A) CSAT / Service
- Symptôme : Top-2 “Attente” < 65 %
Diagnostic : sous-capacité / IVR mal orienté / pics non lissés
Actions : staffing créneau J+7, call-back, priorisation VIP, script triage - Symptôme : Top-2 “Réclamations” < 60 %
Diagnostic : délai de clôture, manque d’autorité au 1er niveau
Actions : SLA par gravité, empowerment, macro-templates, QA hebdo - Symptôme : “Fiabilité” < 70 %
Diagnostic : incidents récurrents / défauts
Actions : bug triage, correctifs P1, post-mortem, comm proactive
B) Marketing (pré-test / post-test)
- Symptôme : “Message clair” < 70 %
Diagnostic : jargon / promesse floue
Actions : reformulation bénéfice, preuve chiffrée, 3 variantes A/B/C - Symptôme : “Intention d’agir” < 65 %
Diagnostic : offre et friction page d’atterrissage
Actions : incentive simple, above-the-fold CTA, baisse champs, preuve sociale
C) UX
- Symptôme : “Tâches clés faciles” < 70 %
Diagnostic : parcours trop long, étapes non visibles
Actions : réduire 1 étape, état de progression, micro-copies, test 5 utilisateurs - Symptôme : “Erreurs aidantes” < 65 %
Diagnostic : messages vagues, absence de rollback
Actions : messages actionnables, annuler/revenir, logs d’événements
(Adaptez la table aux autres contextes : Formation, Engagement.)
3) Feuille “Actions & WAIT” (modèle prêt à coller)
| Contexte | Item | Segment/Canal | Constats | Action | Owner | Date | KPI cible | Statut |
|---|---|---|---|---|---|---|---|---|
| CSAT | Attente | Téléphone (VIP) | Top-2 = 58 % | Call-back + renfort 12–14h | A. Karim | 15/10 | Top-2 ≥ 72 % | En cours |
| UX | Tâches clés | App iOS | 4 étapes | -1 étape + progress bar | L. Nabil | 22/10 | Moy ≥ 4,2 | À faire |
Branchez la Décision Go/No-Go : un WAIT est “déverrouillable” par réussite de ces KPI.
4) Scénarios de poids (pour Go/No-Go)
- Conformité-first (S1) : pondérez sécurité / conformité / fiabilité à 2.
- Expérience-first (S2) : pondérez Top-2 global et Tâches clés à 2.
- ROI-first (S3) : pondérez Intention d’agir (mkt) ou conversion à 2.
Dans GoNoGo_Likert_PassePartout.xlsx, créez S1/S2/S3, basculez le scénario actif et observez la décision.
5) Qualité de données (check rapide)
- Taille d’échantillon : ≥ 30 réponses/segment ; sinon marquer “faible n”.
- Cohérence : mixer items positifs et inversés ; surveiller l’écart-type.
- Stabilité : ne changez pas les items sans versionner (Code_Item, Version).
- Biais canal : comparez Web/App/Magasin ; neutralisez les extrêmes aberrants.
6) Règles de seuils (boîte à outils)
- Top-2 global : 70–80 % selon contexte.
- Plancher par item critique : 60–70 %.
- Moyenne globale (1..5) : 4,0–4,3.
- Dispersion : alerte si σ > 1,0 (fort désaccord).
Décision mixte recommandée :
GO si (Top-2 global ≥ seuil) et (aucun item critique < plancher) ;
WAIT sinon, avec plan d’actions ;
NO GO si écart majeur (ex. sécurité, conformité) ou ROI négatif.
7) Passage en 1→7 (quand affiner)
- Cas d’usage : départager des créations proches, tests UX fins.
- Règles : Top-2 = 6–7 ; normalisation
z=(x−1)/6; item inversé8−x. - Communication : gardez un seul indicateur “exécutif” (Top-2), détaillez en annexe.