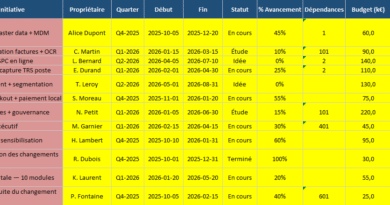
Calculateur Excel Écart-type opérationnel : piloter la variabilité, secteur par secteur
L’écart-type est plus qu’un indicateur statistique, prenons-le pour ce qu’il est réellement : la mesure concrète de la respiration d’un système. Quand cette respiration s’emballe, les coûts montent (rebuts, ruptures, retards) ; quand elle se stabilise, la promesse client tient mieux.
Ce que mesure vraiment l’écart-type
L’écart-type décrit l’amplitude moyenne des écarts autour de la valeur centrale. Plus il est élevé, plus votre processus « bouge ». Deux précisions utiles :
- Population vs échantillon : sur le terrain, vous travaillez souvent avec des échantillons (STDEV.S) ; si vous disposez de l’univers complet, utilisez STDEV.P.
- Comparer des pommes avec des pommes : la dispersion brute n’a de sens qu’avec l’unité et l’échelle (mm, minutes, €/jour…). Pour comparer des entités hétérogènes, passez au coefficient de variation (CV%) = écart-type / moyenne.
Trois règles d’usage universelles
- Choisissez le bon mode (STDEV.S vs STDEV.P) et documentez-le.
- Normalisez avec le CV% pour comparer des lignes/produits/services différents.
- Décidez avec des seuils (S1/S2/S3) alignés sur vos référentiels (ISO, IATF, ITIL, HSE…) :
S1 = zone acceptable, S2 = surveillance renforcée, S3 = alerte et plan d’actions.
Applications par secteur (lectures, pièges, décisions)
Industrie / Qualité (ex. épaisseur, couple, dimension)
- Lecture : un écart-type faible signe un process capable de tenir la tolérance ; CV% suit l’homogénéité entre lots et lignes.
- Pièges : instruments non maîtrisés (MSA / R&R), mélanges de références, saisonnalité matière.
- Décisions : resserrer les paramètres machine, standardiser le set-up, enclencher un plan 6σ si S2/S3 persiste.
Retail / Commerce (ex. ventes quotidiennes)
- Lecture : l’écart-type des ventes traduit la volatilité de la demande ; un CV% élevé = magasin ou SKU « nerveux ».
- Pièges : jours spéciaux (promo, fêtes), cannibalisation, ruptures cachées.
- Décisions : revoir stock mini/sécurités, lisser via assortiments A/B, caler les promos sur la variabilité réelle.
Finance / Comptabilité (ex. rendements journaliers)
- Lecture : l’écart-type des rendements = volatilité ; on l’annualise (×√périodes) pour comparer des actifs.
- Pièges : moyenne proche de zéro → CV% peu interprétable ; queues épaisses (non-normalité) qui gonflent les risques extrêmes.
- Décisions : limites de risque, rééquilibrage, « stop-loss » ; compléter par des indicateurs robustes (MAD, VaR/ES).
Logistique / Délais (ex. retard de livraison)
- Lecture : un écart-type élevé des lead times met à mal la promesse client et le calcul du stock de sécurité.
- Pièges : pics ponctuels (grèves, météo), multiplicités de transporteurs/routings.
- Décisions : fiabiliser partenaires, fenêtres de chargement, buffers adaptés à la dispersion réelle.
Maintenance / Fiabilité (ex. MTBF/MTTR)
- Lecture : la dispersion sur MTBF signale une instabilité de fiabilité ; CV% pointe les machines sensibles.
- Pièges : distributions Weibull fréquentes → la moyenne ne suffit pas.
- Décisions : plan préventif ciblé, pièces critiques en stock, standardisation des causes (AEC/5M/RCFA).
Santé / Services (ex. temps d’attente)
- Lecture : au-delà de la moyenne, la variabilité dicte l’expérience patient/usager.
- Pièges : arrivées par vagues (pédiatrie, urgences), mix de parcours.
- Décisions : triage, créneaux protégés, renforts aux heures de pointe, scénarios « overflow ».
Éducation (ex. notes/20)
- Lecture : un écart-type trop bas peut traduire un test peu discriminant ; trop haut, une hétérogénéité excessive.
- Pièges : tailles d’échantillon réduites, barèmes instables.
- Décisions : recalibrer l’évaluation, travailler l’équité des conditions, utiliser les scores Z pour comparer des groupes.
IT / SLA (ex. minutes d’indisponibilité)
- Lecture : dispersion des indisponibilités = fragilité opérationnelle ; CV% relie stabilité et dette technique.
- Pièges : incidents batchés (post-release), sous-déclaration.
- Décisions : fenêtres de release, feature flags, error budget couplé aux seuils S1/S2/S3.
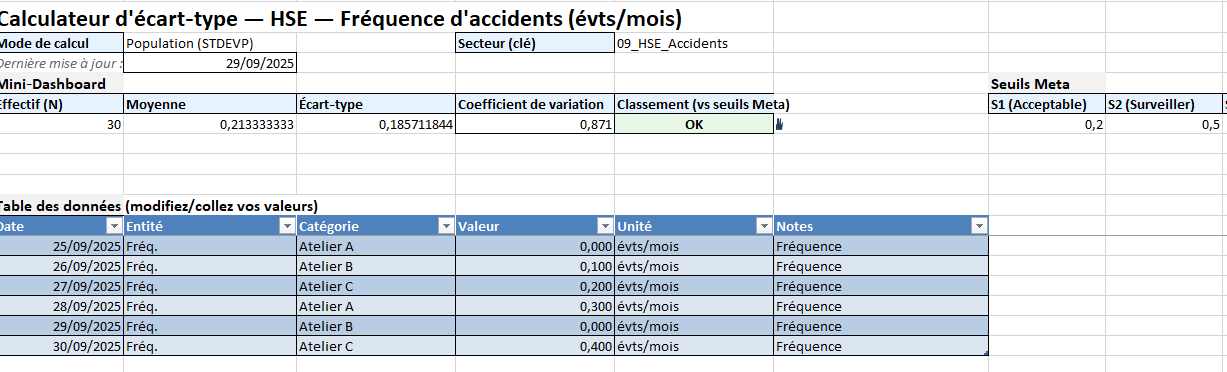
HSE (ex. fréquence d’accidents)
- Lecture : sur faibles volumes, la variabilité suit souvent une logique Poisson (instabilité apparente).
- Pièges : effectifs/exposition non normalisés, sous-déclaration des presqu’accidents.
- Décisions : piloter par taux (par heure travaillée), renforcer la détection des quasi-accidents, boucles QRQC.
Graphiques utiles (et pourquoi)
- Tendance moyenne par date (ligne) : montre si la dispersion suit des régimes (avant/après action, saison).
- Dispersion par catégorie (colonnes) : compare rapidement lignes, magasins, routes, machines.
- Histogramme & boxplot (à ajouter si besoin) : révèle asymétries et extrêmes.
- Cartes de contrôle (I-MR / X-bar-R) (pour l’industrie) : distingue bruit et signal.
Erreurs fréquentes… et corrections immédiates
- Mélanger des unités (min & h, mm & µm) → normaliser avant calcul.
- Séries non stationnaires (changement de produit/process) → segmenter par régime.
- Échantillons trop petits → prudence sur l’interprétation, accumuler des points, utiliser des intervalles.
- Outliers → investiguer (cause spéciale ?) au lieu de les « lisser » systématiquement.
- Moyenne ≈ 0 en finance → privilégier volatilité annualisée et mesures robustes.
Mini-mémo Excel
- Population :
=STDEV.P(plage) - Échantillon :
=STDEV.S(plage) - CV% :
=STDEV.S(plage)/AVERAGE(plage) - Par catégorie (365) :
=STDEV.S(FILTER(Valeur, Catégorie=c)) - Par date (moyenne) (365) :
=MAP(UNIQUE(Date); LAMBDA(d; AVERAGEIF(Date; d; Valeur)))
Checklist d’interprétation (à coller près de votre écran)
- Définir l’unité et l’horizon (jour/semaine/mois).
- Choisir STDEV.S ou STDEV.P et l’écrire dans le fichier.
- Comparer brut et CV%.
- Regarder par catégorie (ligne, magasin, route, machine…).
- Tracer la tendance (avant/après action).
- Positionner S1/S2/S3 et décider : tenir, surveiller, agir.
Trois alternatives de formulation (pour remplacer votre phrase)
- « L’écart-type mesure la respiration d’un système : plus elle est régulière, plus la promesse tenue au client est solide. »
- « En un nombre, l’écart-type raconte la stabilité de votre flux : il sépare le bruit normal des vraies dérives. »
- « L’écart-type capture la variabilité utile au pilotage : quand il grimpe, la qualité, les délais et les coûts s’en ressentent. »
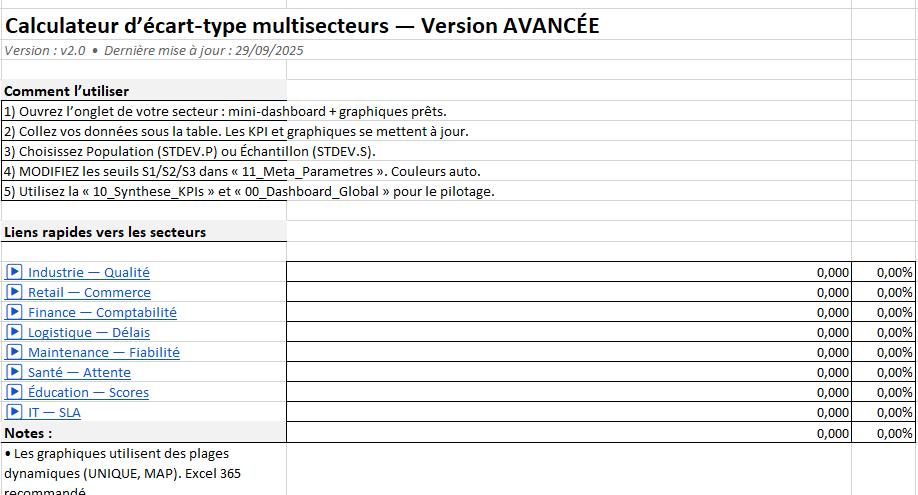
Calculateur Excel Écart-type opérationnel – Classeur Excel avec graphiques
- 00_Accueil_ModeEmploi
Guide express + liens vers chaque secteur. Indique la version et la date. - 00_Dashboard_Global
Graphique colonnes Écart-type par secteur + courbe CV % sur axe secondaire (vue d’ensemble immédiate). - Feuilles secteurs
01→09(Industrie, Retail, Finance, Logistique, Maintenance, Santé, Éducation, IT, HSE)- Mini-dashboard en haut : N, moyenne, écart-type, CV %, statut (OK/Surv./Alerte) + sparkline.
- Deux graphiques prêts :
- Ligne – tendance moyenne par date (régimes avant/après action).
- Colonnes – écart-type par catégorie (lignes, magasins, routes…).
- Table de données (Date, Entité, Catégorie, Valeur, Unité, Notes).
- Sélecteur Population (STDEV.P) / Échantillon (STDEV.S).
- Calculs dynamiques (UNIQUE/FILTER/MAP) → mise à jour auto après collage.
- 10_Synthese_KPIs
Tableau récapitulatif par secteur : SD, CV %, statut (alimentation des graphes globaux). - 11_Meta_Parametres
Seuils S1/S2/S3 par secteur (pilotent les couleurs et le statut).
À utiliser : collez vos données sous la table de chaque secteur → KPIs et graphiques se recalculent. Ajustez les seuils dans 11_Meta_Parametres. (Excel 365 recommandé pour les formules dynamiques.)
Le fichier :
En pratique, que faire demain matin ?
- Ouvrir votre jeu de données, isoler une période homogène.
- Calculer écart-type et CV%, puis segmenter par catégorie.
- Colorer S1/S2/S3, cartographier les causes (5M, Ishikawa) et fixer 3 actions : une sur la mesure (MSA), une sur le process (réglage, standard), une sur la charge (lissage).
- Re-mesurer sous 2 semaines : la baisse de l’écart-type est votre baromètre de progrès.
Cas particuliers & interprétation de l’écart-type — le guide terrain
Ci-dessous, 15 situations piégeuses mais fréquentes où l’écart-type demande une lecture particulière. Pour chacune : symptôme → interprétation → quoi faire.
1) Échantillon trop petit (n < 10)
Symptôme : écart-type instable, change au moindre ajout de point.
Interprétation : forte incertitude d’estimation.
Action : utiliser STDEV.S, afficher un IC (ex. ±30–50% à ce n), cumuler des points ou regrouper par sous-groupes (SPC).
2) Moyenne proche de zéro (finance, écarts signés)
Symptôme : CV% explose (SD / moyenne ≈ infini).
Interprétation : le CV est non pertinent quand μ ≈ 0.
Action : comparer des SD absolus, travailler en log-retours ou utiliser des mesures robustes (MAD, IQR).σ_annuel ≈ σ_journalier × √252 (finance).
3) Distribution asymétrique ou à queues épaisses
Symptôme : histogramme « penché », outliers fréquents.
Interprétation : la moyenne est peu représentative ; l’écart-type gonfle.
Action : passer en médiane + MAD, tester une transformation (log, Box-Cox), segmenter par familles.
4) Mélange de populations (Simpson)
Symptôme : écart-type global élevé, par sous-groupe faible.
Interprétation : mélange de lignes/produits/magasins.
Action : stratifier (Catégorie, Ligne, Route…). Lire SD intra-groupe vs inter-groupe.
5) Outliers / causes spéciales
Symptôme : quelques points extrêmes tirent la SD.
Interprétation : événements assignables (set-up raté, promo, bug release).
Action : investiguer, corriger la cause, documenter. N’exclure qu’avec règle écrite (ex. winsorisation 1–99%).
6) Non-stationnarité (changement de régime)
Symptôme : avant/après action, la variabilité change.
Interprétation : SD globale n’a pas de sens.
Action : découper en phases, utiliser SD glissante (fenêtre 20–30 points), ou cartes de contrôle I-MR / X-bar-R.
7) Variance qui croît avec le niveau (effet entonnoir)
Symptôme : plus la moyenne est haute, plus SD est grande.
Interprétation : hétéroscédasticité.
Action : raisonner en CV%, ou transformer (log, √x) pour stabiliser la variance.
8) Comptages rares (HSE, incidents, défauts)
Symptôme : beaucoup de zéros, quelques pics.
Interprétation : proche d’un process Poisson ; SD ≈ √λ.
Action : piloter en taux (évts / heures-exposition), cartes c/u, comparer des périodes longues.
9) Données censurées (MTBF/fiabilité)
Symptôme : pannes non observées dans la fenêtre (censure à droite).
Interprétation : la SD naïve biaisée.
Action : analyse Weibull/survie, prendre en compte la censure ; comparer par machine (mêmes expositions).
10) Proportions / taux bornés [0 ; 1]
Symptôme : taux de défaut, dispo, taux d’occupation.
Interprétation : variance binomiale : SD(p) ≈ √(p(1−p)/n), sensible au dénominateur.
Action : toujours afficher n, utiliser cartes p/np, lire P90 plutôt que la seule SD quand le ressenti utilisateur compte.
11) Files d’attente (santé, support)
Symptôme : temps d’attente très dispersés, CV≈1.
Interprétation : comportements exponentiels/Erlang normaux.
Action : piloter par percentiles (P80/P90), lissage des arrivées et capacité aux pointes, plutôt que chercher une SD « basse » absolue.
12) Zéros en masse (IT/SLA)
Symptôme : médiane = 0, mais SD > 0.
Interprétation : modèle à deux états (zéro ou incident).
Action : suivre fréquence d’incidents + gravité séparément ; SD seule sous-informe.
13) Logistique : mélanges de routes / transporteurs
Symptôme : SD lead time élevée, carte par route très différente.
Interprétation : mix de schémas d’acheminement.
Action : segmentation (Route×Transporteur), stock de sécurité par lane, pénalités ciblées.
14) Mesure elle-même variable (MSA / R&R)
Symptôme : SD process ≈ SD instrument.
Interprétation : la capabilité est faussée.
Action : évaluer σ_mesure (R&R) et approcher σ_process² ≈ σ_total² − σ_mesure². Sans ça, SD surestimée.
15) Effet d’agrégation temporelle
Symptôme : SD hebdo < SD journalière.
Interprétation : l’agrégation lisse la variabilité.
Action : choisir l’horizon cohérent avec vos décisions (jour pour opérations, semaine pour S&OP), comparer à granularité constante.
Rappels sectoriels en 20 secondes
- Industrie : SD basse = capabilité (Cp/Cpk) potentiellement bonne ; vérifier d’abord MSA.
- Retail : dé-saisonnaliser (avant/après promo), lire CV% par SKU×magasin.
- Finance : SD = volatilité ; préférer log-retours, regarder queues (kurtosis).
- Logistique : SD lead time → stock de sécu ; séparer causes structurelles vs aléas.
- Maintenance : distributions Weibull ; éviter SD naïve avec censure.
- Santé/Services : viser P90 plus que SD ; dimensionner les pics.
- IT : séparer fréquence et durée ; SD globale trompeuse.
- HSE : raisonner en taux exposés, fenêtres plus longues.
Mini-formulary (pratique)
CV% = STDEV.S(plage) / AVERAGE(plage)
SD pondérée ≈ sqrt( Σ w_i (x_i − μ_w)^2 / Σ w_i ), μ_w = Σ w_i x_i / Σ w_i
Poisson SD ≈ √λ (λ = moyenne des comptages)
Binomiale SD ≈ √(p(1−p)/n)
Vol annualisée σ_ann = σ_day × √252
Variance process (approx.) σ_proc² ≈ σ_total² − σ_mesure²
Grille d’interprétation (à appliquer dans votre fichier)
- Choisir le bon mode (STDEV.S vs STDEV.P) et l’écrire.
- Vérifier stationnarité et mélanges → segmenter.
- Regarder CV% quand l’échelle varie (sinon, SD absolue).
- Lire par catégorie (ligne, route, machine, magasin).
- Compléter par percentiles si le ressenti/SLAs prime.
- Décider via seuils S1/S2/S3 → tenir / surveiller / agir.