Convertir un fichier .txt en liste Python
Recommandés
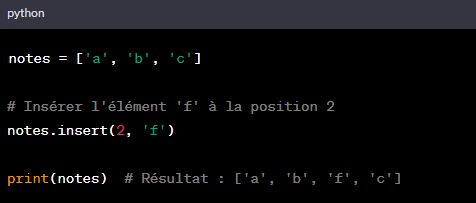

La manipulation de fichiers texte est une tâche courante en programmation, notamment en Python. Dans cet article, nous allons explorer différentes méthodes pour convertir le contenu d’un fichier texte (.txt) en une liste Python.
Méthode 1 : Lecture ligne par ligne
La méthode la plus simple pour convertir un fichier texte en liste Python est de lire le fichier ligne par ligne et d’ajouter chaque ligne à une liste. Voici comment cela peut être fait :
# Ouvrir le fichier en mode lecture
with open('fichier.txt', 'r') as f:
# Lire les lignes du fichier
lines = f.readlines()
# Supprimer les caractères de nouvelle ligne
lines = [line.strip() for line in lines]
# Afficher la liste résultante
print(lines)Cette méthode ouvre le fichier en mode lecture (‘r’) et utilise la méthode readlines() pour lire toutes les lignes du fichier et les stocker dans une liste. Ensuite, nous utilisons une compréhension de liste pour supprimer les caractères de nouvelle ligne (\n) de chaque ligne.
Méthode 2 : Lecture du contenu complet
Si le fichier texte est petit et peut tenir en mémoire sans problème, vous pouvez également lire son contenu complet et le diviser en lignes à l’aide de la méthode split().
# Ouvrir le fichier en mode lecture
with open('fichier.txt', 'r') as f:
# Lire le contenu complet du fichier
content = f.read()
# Diviser le contenu en lignes
lines = content.split('\n')
# Afficher la liste résultante
print(lines)Cette méthode lit tout le contenu du fichier en une seule fois avec read(), puis divise ce contenu en lignes en utilisant la méthode split() avec le délimiteur ‘\n’.
Méthode 3 : Utilisation de la bibliothèque pathlib
Si vous travaillez avec des fichiers dans des projets Python plus importants, vous pouvez utiliser la bibliothèque pathlib pour gérer les chemins de fichiers de manière plus efficace. Voici comment vous pourriez l’utiliser pour convertir un fichier en liste :
from pathlib import Path
# Définir le chemin du fichier
file_path = Path('fichier.txt')
# Lire les lignes du fichier
lines = file_path.read_text().splitlines()
# Afficher la liste résultante
print(lines)Cette méthode utilise Path('fichier.txt') pour créer un objet de chemin de fichier, puis read_text() pour lire le contenu du fichier en tant que chaîne de caractères. Enfin, splitlines() divise cette chaîne en une liste de lignes.
Voici des cas particuliers avec des extraits de code pour chaque exemple :
Exemple 1 : Analyse de données d’un fichier de logs
Cas particulier : Compter le nombre d’accès réussis et d’accès échoués dans les logs.
# Méthode 1 : Lecture ligne par ligne
with open('logs.txt', 'r') as f:
lines = f.readlines()
# Compter le nombre d'accès réussis (code 200) et d'accès échoués (autres codes)
successful_accesses = sum(1 for line in lines if line.startswith('200'))
failed_accesses = sum(1 for line in lines if not line.startswith('200'))
print("Nombre d'accès réussis:", successful_accesses)
print("Nombre d'accès échoués:", failed_accesses)Exemple 2 : Traitement de données financières
Cas particulier : Trouver la date du jour avec le prix de clôture maximal.
# Méthode 2 : Lecture du contenu complet
with open('stock_prices.txt', 'r') as f:
content = f.read()
# Diviser le contenu en lignes de données (date, prix)
data = [line.split(',') for line in content.split('\n') if line]
# Trouver la date avec le prix de clôture maximal
max_close_price_date = max(data, key=lambda x: float(x[1]))[0]
print("Date avec le prix de clôture maximal:", max_close_price_date)Exemple 3 : Analyse de texte pour le traitement du langage naturel (NLP)
Cas particulier : Trouver les 10 mots les plus fréquents dans le corpus.
# Méthode 3 : Utilisation de la bibliothèque pathlib
from collections import Counter
from pathlib import Path
file_path = Path('corpus.txt')
# Lire le contenu du fichier
corpus = file_path.read_text()
# Tokeniser le corpus en mots
words = corpus.split()
# Compter la fréquence de chaque mot
word_counts = Counter(words)
# Trouver les 10 mots les plus fréquents
top_10_words = word_counts.most_common(10)
print("Les 10 mots les plus fréquents:", top_10_words)Exemple 4 : Prétraitement de données pour l’apprentissage automatique
Cas particulier : Supprimer les lignes avec des valeurs manquantes dans une colonne spécifique.
# Méthode 1 : Lecture ligne par ligne
with open('dataset.txt', 'r') as f:
lines = f.readlines()
# Supprimer les lignes contenant des valeurs manquantes dans la deuxième colonne
cleaned_lines = [line.strip() for line in lines if line.split(',')[1].strip()]
print("Nombre de lignes après nettoyage:", len(cleaned_lines))Ces cas particuliers démontrent comment adapter l’extraction et le traitement des données en fonction des besoins spécifiques de chaque application, en utilisant des extraits de code Python pour illustrer chaque scénario.
Voici des exemples de cas particuliers avec des extraits de code pour chaque exemple :
Exemple 1 : Analyse de données d’un fichier de logs
Cas particulier : Calculer le nombre d’accès réussis et échoués pour un certain jour.
Supposons que chaque ligne du fichier de logs soit au format "date heure code". Nous voulons compter le nombre d’accès réussis (code 200) et échoués (codes autres que 200) pour une date donnée.
# Méthode 1 : Lecture ligne par ligne
with open('logs.txt', 'r') as f:
lines = f.readlines()
# Définir la date pour laquelle nous voulons compter les accès
target_date = "2024-02-15"
# Compter le nombre d'accès réussis et échoués pour la date donnée
successful_accesses = sum(1 for line in lines if line.startswith(target_date) and "200" in line)
failed_accesses = sum(1 for line in lines if line.startswith(target_date) and "200" not in line)
print("Nombre d'accès réussis le", target_date + ":", successful_accesses)
print("Nombre d'accès échoués le", target_date + ":", failed_accesses)Exemple 2 : Traitement de données financières
Cas particulier : Calculer le rendement quotidien de l’action.
Supposons que chaque ligne du fichier stock_prices.txt soit au format "date,prix_cloture". Nous voulons calculer le rendement quotidien en pourcentage de l’action.
# Méthode 2 : Lecture du contenu complet
with open('stock_prices.txt', 'r') as f:
content = f.read()
# Diviser le contenu en lignes de données (date, prix)
data = [line.split(',') for line in content.split('\n') if line]
# Calculer le rendement quotidien en pourcentage
returns = [(data[i][0], ((float(data[i][1]) - float(data[i-1][1])) / float(data[i-1][1])) * 100) for i in range(1, len(data))]
print("Rendement quotidien:", returns)Exemple 3 : Analyse de texte pour le traitement du langage naturel (NLP)
Cas particulier : Trouver les phrases les plus longues dans le corpus.
# Méthode 3 : Utilisation de la bibliothèque pathlib
from pathlib import Path
file_path = Path('corpus.txt')
# Lire le contenu du fichier
corpus = file_path.read_text()
# Diviser le corpus en phrases
sentences = corpus.split('.')
# Trouver les phrases les plus longues
longest_sentences = sorted(sentences, key=len, reverse=True)[:5]
print("Phrases les plus longues:", longest_sentences)Exemple 4 : Prétraitement de données pour l’apprentissage automatique
Cas particulier : Supprimer les lignes contenant des valeurs aberrantes dans une colonne spécifique.
Supposons que chaque ligne du fichier dataset.txt contienne des données au format "attribut1,attribut2,attribut3". Nous voulons supprimer les lignes dont la valeur de attribut3 est en dehors d’une plage spécifique.
# Méthode 1 : Lecture ligne par ligne
with open('dataset.txt', 'r') as f:
lines = f.readlines()
# Définir la plage de valeurs autorisées pour attribut3
min_value = 10
max_value = 100
# Supprimer les lignes avec des valeurs aberrantes dans attribut3
cleaned_lines = [line.strip() for line in lines if min_value <= int(line.split(',')[2]) <= max_value]
print("Nombre de lignes après nettoyage:", len(cleaned_lines))Ces exemples montrent comment adapter les méthodes de traitement des données pour répondre à des cas particuliers spécifiques, en utilisant des extraits de code pour illustrer chaque scénario.
Voici comment ces erreurs courantes peuvent être illustrées avec des extraits de code :
1. Oublier de gérer les erreurs de fichier inexistant
try:
with open('fichier_inexistant.txt', 'r') as f:
lines = f.readlines()
except FileNotFoundError:
print("Le fichier spécifié n'existe pas.")2. Ne pas fermer correctement le fichier après lecture
f = open('fichier.txt', 'r')
lines = f.readlines()
# Oubli de fermer le fichier
# f.close() # Ne pas oublier de fermer le fichier après utilisation3. Ne pas traiter les caractères spéciaux ou les encodages incorrects
# Ouvrir le fichier avec un encodage spécifique
with open('fichier.txt', 'r', encoding='utf-8') as f:
lines = f.readlines()4. Ne pas gérer correctement les sauts de ligne
# Supprimer les caractères de saut de ligne
lines = [line.strip() for line in lines]5. Ne pas considérer la taille du fichier
# Lecture complète du contenu d'un fichier volumineux
with open('fichier_volumineux.txt', 'r') as f:
content = f.read()6. Assumer une structure de données uniforme
# Assumer une structure uniforme alors que le fichier a une structure variable
for line in lines:
# Traitement de chaque ligne supposée avoir une structure spécifique
pass7. Oublier de gérer les caractères d’échappement
# Traitement incorrect des caractères d'échappement
# Ne pas oublier de traiter correctement les caractères d'échappement
# lors de la lecture du fichier
with open('fichier.txt', 'r') as f:
for line in f:
# Traitement des caractères d'échappement
line = line.replace('\n', '') # Supprimer le saut de ligne
line = line.replace('\t', ' ') # Remplacer les tabulations par des espacesEn évitant ces erreurs courantes lors de la manipulation de fichiers texte en Python, vous pouvez rendre votre code plus robuste et moins sujet aux erreurs.
Conclusion
Dans cet article, nous avons examiné plusieurs façons de convertir le contenu d’un fichier texte en une liste Python. La méthode que vous choisissez dépendra de la taille du fichier, de vos préférences personnelles et de la complexité de votre projet. Que vous choisissiez de lire ligne par ligne, de lire le contenu complet ou d’utiliser pathlib, vous pouvez maintenant manipuler facilement des fichiers texte dans vos programmes Python.
Recommandés

