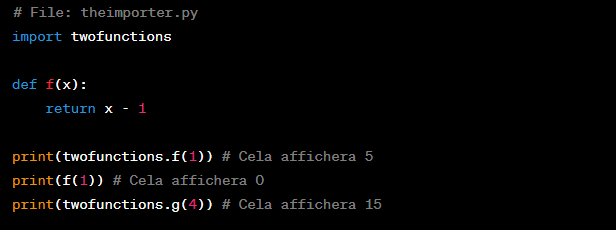
Tutoriel langage Python: Analyse du temps d’exécution
Recommandés


Dans ce tutoriel langage python, nous discutons l’analyse du temps d’exécution d’un code en python.

Installer IDE python
Notre but en programmation est d’écrire du code correct, efficace et lisible. Il existe diverses approches pour atteindre la correction. Lorsque des erreurs surviennent, nous déboguons, et l’inefficacité peut émerger à mesure que les entrées augmentent, rendant la détection de problèmes plus complexe.
Nous cherchons à établir un vocabulaire pour évaluer l’efficacité de notre code. Les termes « rapide » ou » lent » sont insuffisants. L’efficacité varie avec l’entrée et la plateforme. Nos objectifs sont exigeants :
Nous atteindrons ces objectifs grâce à une analyse asymptotique. En mesurant le temps d’exécution et en observant comment il varie avec la taille des entrées, nous déterminerons l’efficacité de nos programmes.
Pour démarrer, examinons les écarts de temps d’exécution entre diverses fonctions effectuant la même tâche. Ces fonctions partagent un comportement ou une sémantique similaires. Par exemple, considérons une fonction prenant une liste en entrée et renvoyant True si elle contient des doublons, sinon False.
```
def duplicates1(L):
# Récupère la longueur de la liste L
n = len(L)
# Parcourt la liste L avec deux boucles imbriquées
for i in range(n):
for j in range(n):
# Si les indices i et j sont différents et les éléments correspondants sont identiques
if i != j and L[i] == L[j]:
return True # Il y a des doublons, donc retourne True
# Si aucune correspondance n'est trouvée, retourne False (aucun doublon)
return False
# Tests d'assertion pour vérifier si la fonction fonctionne correctement
assert(duplicates1([1, 2, 6, 3, 4, 5, 6, 7, 8])) # La liste contient des doublons, donc True
assert(not duplicates1([1, 2, 3, 4])) # Aucun doublon dans cette liste, donc False
```
Le code `duplicates1` vérifie si une liste `L` contient des doublons en comparant chaque paire d'éléments dans la liste. Si des doublons sont trouvés, la fonction renvoie `True`, sinon elle renvoie `False`. Les tests d'assertion vérifient le comportement de la fonction pour des cas d'utilisation spécifiques.Quelle est la vitesse de ce code ?
Pour répondre à cette question, la méthode la plus directe consiste à exécuter le programme et à chronométrer son temps d’exécution. Voici comment cela pourrait être réalisé.
Vous pouvez utiliser le code Python suivant pour mesurer le temps d’exécution de la fonction duplicates1 en fonction de la valeur de n. Assurez-vous d’avoir déjà défini la fonction duplicates1 et importé le module time.
import time
for i in range(5):
n = 1000
start = time.time()
duplicates1(list(range(n)))
timetaken = time.time() - start
print("Time taken for n =", n, ":", timetaken)Ce code exécute la fonction duplicates1 cinq fois pour une liste générée de longueur n = 1000. Il mesure le temps pris par chaque exécution et l’affiche à l’écran. Cela vous permettra d’obtenir une idée du temps d’exécution de la fonction pour cette valeur spécifique de n.
Stabilité des temps d’exécution et moyennage des résultats
Nous observons une variation de temps d’exécution, principalement due à la charge de travail de l’ordinateur, à l’exécution de tâches système et à des différences matérielles. Pour obtenir des résultats plus stables, nous exécutons le code plusieurs fois, puis calculons la moyenne, lissant ainsi les variations. Cette idée sera étendue à un travail plus général où nous exécuterons une fonction donnée sur des listes de différentes longueurs, moyennant les temps d’exécution pour chaque taille de liste.
```
import time
def timetrials(func, n, trials=10):
totaltime = 0
for i in range(trials):
start = time.time()
func(list(range(n)))
totaltime += time.time() - start
print("moyenne = %10.7f pour n = %d" % (totaltime / trials, n))
```
Ce code Python définit une fonction appelée `timetrials` qui mesure le temps d’exécution moyen d’une fonction donnée `func` pour un nombre de `n` essais spécifiés. Il exécute la fonction `func` sur une liste de longueur `n` pour chaque essai et calcule le temps d’exécution moyen sur l’ensemble des essais.
Optimisation du code pour réduire les opérations redondantes
Essayons d’optimiser notre code pour gagner en efficacité. Des améliorations simples peuvent éliminer des situations où nous effectuons un travail inutile ou redondant.
Dans la fonction « duplicates1, » nous comparons chaque paire d’éléments deux fois, car les indices « i » et « j » s’étendent sur tous les indices « n. » Nous pouvons éviter cette redondance en utilisant une astuce courante qui limite la boucle de « j » à ne pas inclure « i. » Voici comment cela modifie le code.
def duplicates2(L):
n = len(L)
for i in range(1, n):
for j in range(i):
if L[i] == L[j]:
return True
return False
for n in [50, 100, 200, 400, 800, 1600, 3200]:
timetrials(duplicates2, n)Ce code Python définit une fonction duplicates2 qui vérifie la présence de doublons dans une liste L. Ensuite, il exécute cette fonction sur des listes de différentes tailles [50, 100, 200, 400, 800, 1600, 3200] pour mesurer les temps d’exécution moyens à l’aide de la fonction timetrials.
Optimisation de la boucle avec les compréhensions python
Une alternative Python au type de boucle utilisé dans duplicates2 est d’utiliser une fonction qui prend une collection itérable de booléens et renvoie True si tous les booléens sont vrais. Vous pouvez créer cette collection itérable en utilisant des compréhensions. Cette approche peut être plus concise.
def duplicates3(L):
n = len(L)
return any(L[i] == L[j] for i in range(1, n) for j in range(i))
for n in [50, 100, 200, 400, 800, 1600, 3200]:
timetrials(duplicates3, n)Ce code Python définit une fonction duplicates3 qui vérifie s’il existe des doublons dans une liste L. Il utilise une approche basée sur les compréhensions pour simplifier la boucle et améliorer l’efficacité. Ensuite, il exécute cette fonction avec différentes tailles de listes et mesure le temps d’exécution moyen.
Optimisation de la recherche de doublons grâce au tri de la liste
La dernière optimisation simplifie le code, améliorant sa lisibilité, mais n’affecte pas la vitesse d’exécution. Pour des améliorations significatives, une nouvelle approche est nécessaire. Une option consiste à trier la liste et à comparer les éléments adjacents, car les doublons seront voisins après le tri.
def duplicates4(L):
n = len(L)
L.sort()
for i in range(n-1):
if L[i] == L[i+1]:
return True
return False
def duplicates5(L):
n = len(L)
L.sort()
return any(L[i] == L[i+1] for i in range(n-1))
def duplicates6(L):
s = set()
for e in L:
if e in s:
return True
s.add(e)
return False
def duplicates7(L):
return len(L) != len(set(L))
def duplicates8(L):
s = set()
return any(e in s or s.add(e) for e in L)
# Pour chaque taille de liste 'n' spécifiée :
for n in [50, 100, 200, 400, 800, 1600, 3200]:
# Affiche le résultat de chaque algorithme en utilisant la fonction 'timetrials'.
print("Quadratic: ", end="")
timetrials(duplicates3, n)
print("Sorting: ", end="")
timetrials(duplicates5, n)
print("Sets: ", end="")
timetrials(duplicates7, n)
print('---------------------------')Ce code définit plusieurs fonctions pour vérifier la présence de doublons dans une liste et les teste pour différentes tailles de liste.
Quelques points clés à retenir sont les suivants :
- Les structures de données sont cruciales pour l’efficacité. Les opérations de test d’appartenance et la création d’ensembles peuvent considérablement améliorer les performances.
- Les hypothèses faites sur les éléments de la liste, telles que leur comparabilité ou leur hachage, sont essentielles. Cela concerne le type des éléments, pas seulement leur classe. Il s’agit d’une analogie de frappe de canard.
- L’hypothèse est que certaines méthodes peuvent être appelées sur les éléments. L’utilisation d’expressions de générateur est également une pratique courante.
- L’idée principale à retenir est que le temps d’exécution dépend de la taille de l’entrée. Plus la taille de l’entrée est grande, plus le temps augmente. Parfois, l’écart entre deux morceaux de code augmentera à mesure que la taille de l’entrée augmente.
Recommandés