Cours Cobol et théorie de programmation : LE LANGAGE COBOL
Cours et tutoriel Cobol / tuto Cobol en ligne / formation Cobol
Bienvenue au cours cobol de base qui traite le langage Cobol ou les éléments nécessaire à l’écriture d’un programme cobol
Remarque: ll convient de noter que nous parlons du langage Cobol des années 70, et ce cours profite premièrement à ceux qui s’intéressent à l’histoire de l’informatique.
on peut trouver aussi en cobol, comme dans toute langue écrite, des styles différents suivant chaque programmeur.
Chaque programmeur peut écrire son programme dans le style de Balzac, un autre dans le style de Flaubert. en effet, un certain nombre de mots est facultatifs et ne servent qu’a une meilleure compréhension du programme.
Leur présence ou leur absence n’affecte en rien 1’instruction et, ils n’interviennent que pour la clarté de la lecture. D’autres mots peuvent être abrégés
D’autre part, pour définir les informations propres à son problème, le programmeur doit utiliser des mots qu’il crée lui-même et qui doivent respecter certaines règles. Pour le choix de ces mots 1’imagiation du programmeur est mise à contribution. De plus, parmi tous les ordres COBOL mis à la disposition du programmeur, ce dernier peut en utiliser certains plus souvent au détriment d’autres qui pourraient convenir aussi bien. Il peut grouper toutes ces instructions en phrases plus ou moins longues et toutes ces phrases en un certain nombre de paragraphes eux-mêmes plus ou moins longs. Ainsi deux programmes sémantiquement identiques, peuvent-ils se présenter sous deux formes syntaxiques très différentes :
-l’un se présentant avec des phrases longues, comportant tous les mots facultatifs;
-1’autre n’utilisant que les mots obligatoires et les abréviations et se présentant sous forme de petites phrases concises.
CARACTERES UTILISES POUR L’ECRITURE D’UN PROGRAME
Comme tout langage écrit, COBOL s’exprime à l’aide de caractères. Nous avons vu précédemment des caractères qui nous permettaient de représenter l’information. Ce n’est qu’une partie de ces caractères qui peut être utilisée pour l’écriture d’un programme. Ces caractères permettent d’écrire des mots et des valeurs utilisés dans le programme et de mettre la ponctuation.
Les caractères utilisables sont :
a) les 10 chiffres décimaux (0 ã 9);
b) les 26 lettres majuscules de 1’alphabet (A ã Z);
c) les caractères spéciaux suivants:
+ (signe plus) utilisé pour 1’arithmé-tique et aussi comme caractère d’édition;
– (signe moins) utilisé pour 1’arithmé-tique et aussi comme caractère d’édition. Ce signe est également employé comme trait d’union (hyphen);
*(Astérisque) utilisé en arithmétique pour la multiplication et aussi comme caractère d’édition;
/(Barre de fraction) utilisée en arithmétique pour la division;
< (signe inférieur)
> (signe supérieur)
) (parenthèse gauche)
(parenthèse droite)
(guillemet ou apostrophe ou quote);
(point-virgule);
pour la position du point décimal des
valeurs numériques. C’est la convention
Anglo-saxonne de l’écriture des
nombres qui est normalement utilisée.
(signe dollar) utilisé pour les éditions
Comme nous 1’avons dit précédemment, le CoboL, ayant été crée pour traiter des problèmes de gestion, permet de faire principalement du traitement de 1’information. I1 peut traiter d’importantes quantités de données, assure donc, dans les meilleures conditions, le traitement de gros fichiers d’informations.
Lors de la rédaction d’un programme, un travail important consiste à définir d’une manière précise et non ambigüe, toute 1’énorme masse d’informations que 1’ordinateur aura à traiter. La description des fichiers constitue donc une partie très importante de la rédaction du programme.
Un programme comprend toujours quatre parties, appelées « DIVI-
SIONS »:
– Identification Division;
– Environment Division;
-Data Division;
– Procédure Division.
Chacune de ces divisions est composée de sections, el1es-mêmes subdivisées en paragraphes.
Nous avons consacré dans cet ouvrage un chapitre ã chacune de ces. Divisions. Nous ne donnons ici qu’un aperçu de leur rôle.
Identification Division
vide
Environment Division
Cette division comprend deux sections. La première ppelée » configuration Section ». la seconde appelée « Input-Output Section ».
a. Configuration Section.
Cette section est généralement courte et permet de définir sur quels ordinateurs vont se dérouler les travaux.
b. Input-Output Section. Cette section est divisée elle-même en deux paragraphes. Dans cette section on affecte les fichiers à leurs unités périphériques et on les définit physiquement.
Data Division.
C’est dans cette division qu’est faite la description des fichiers, des zones de manœuvre et des zones de constantes. Elle est divisée en plusieurs sections :
– File Section : relative aux fichiers.
– Working-Storage Section : relative aux zones de manœuvre ou zones de travail.
-Une section dont l’appellation varie avec les constructeurs et qui permet d’établir la liaison entre le programme principal et des sous-programmes écrits en COBOL ou en d’autres langages.
-Constant Section : relative aux zones de constantes. Cette section tend ã disparaître.
Report Section : cette section n’est utilisée, que lorsque le compilateur que l’on a à sa disposition possède le sous-ensemble « Report-Writer ». Cet ensemble d’édition très particulier n’est pas considéré dans cet ouvrage. Cette section est la dernière de la Data Division.
Procedure Division
C’est dans cette division que l’on écrit les instructions qui vont permettre de traiter les informations définies dans les divisions précédentes. Cette division peut être composée de sections, elles-même divisées en paragraphes. Le nombre de sections et de paragraphes n’est pas limité. Chaque paragraphe contient un nombre quelconque d’ordres COBOL.
TYPES DE MOTS UTILISES
Tous les ordres COBOL s’écrivent bien entendu ã l’aide de mots. Certains sont laissés au libre choix du programmeur (noms et constantes), d’autres sont spécifiques du langage (verbes et mots réservés).
Les noms.
Dans ce paragraphe sont définis les différents types de noms qui peuvent être utilisés par le programmeur, ce sont :
-Nom-donnée.
-Nom-procédure.
-Nom-condition.
-Nom-fichier.
-Nom-hardware encore appelé Nom-unité.
– Nom-bibliothèque.
-Nom-qualifié.
-Nom-indicé
Pour chacun de con types de nome, nous donnons sa définition, ses règles de formation, la division du programme ou il est utilisé et des exemples
NOM-DONNEE
a. Définition.
c’est 1a traduction du mot anglais « data name » Toutes les informations qui seront traités dans les programmes Cobol sont identifiées par un nom qui est appellế « nom-donnée ».
b. Formation et écriture.
:
Un nom-donnée est formé par une combinaison des caractères suivants:
– 1es 10 chiffres de 0ã9;
– les 26 lettres majuscules de Aã Z;
– 1e trait d’union.
Remarque.
Pour distinguer la lettre 0 du chiffre 0, on a pris 1’habitude de barrer la lettre Ø dans le programme.
Un nom-donnée est une suite de 1 ã 30 de ces caractêres. Il doit contenir au moins un caractêre alphabétique ã un endroit quelconque (pas nécessairement le premier caractêre de gauche). Il peut être com-posé de plusieurs mots, réunis par des traits d’union. Ces derniers ne peuvent être ni le premier ni le dernier caractêre du nom-donnée et il ne peut pas y en avoir deux consécutifs.
c. Partie du programme où il est défini.
Il est défini dans la Data Division.
. Parties du programme où il est utilisé.
Il peut être utilisé dans toutes les divisions.
cobol
a.Définition
Le nom-procédure est un nom qui sert a identifier un paragraphe ou un groupe de paragraphes (une section) dans la Procédure Division d’un programme.
b. Formation et écriture.
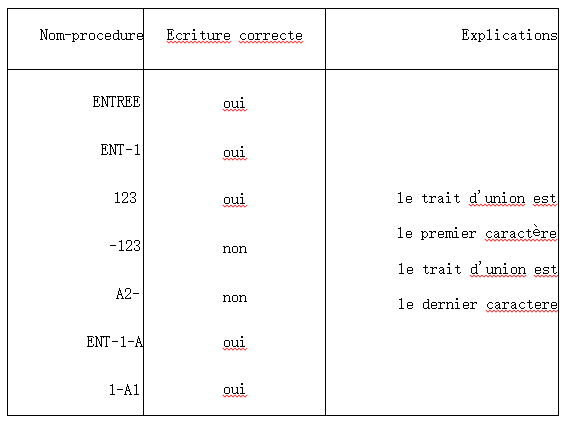
Le nom-procédure obéit aux mêmes règles que celles du nom-donnée. Toutefois, il peut ne contenir que des caractères numériques.
Remarquons que dans le cas d’un nom-procédure entièrement numérique, ce n’est pas la valeur numérique qui est prise en compte, mais la suite de caractères considérée comme représentant un mot.
Ainsi, pour se référer au nom-procédure 123 il faut 1’appeler obligatoirement 123 et non 0123 ou encore 00123.
Partie du programme où il est défini
Il est défini par sa seule présence dans la Procedure Division (c’est l’étiquette d’un groupe d’ordres).
Parties du programme où il est utilisé. Il est utilisé pour découper le programme en paragraphes, ce qui permet dans la Prodecure Division, de sauter une série d’instructions et d’aller exécuter le paragraphe qui a pour étiquette ce nom-procédure.
Cobol: Exemples de noms-procédure
cours Cobol
NOM-FICHIER
a. Définition.
I1 est appelé File-Name en anglais. C’est le nom, affecté par le programmeur, qui sert ã désigné le fichier dans tout le programme.
b.Formation et écriture.
Le nom-fichier obéit aux mêmes règles que celles du nom-donnée.
Partie du programme où il est défini
Il est défini dans l’Input-Output Section de l’environment division de façon à signaler l’ordinateur sur quel type d’unité périfirique se trouve le fichier. le nom-fichier apparaît aussi dans le file section de la Data Division qui est la partie du programme dans laquelle le fichier correspond est décrit.
Partie du programme où il est utilisé
Il est utilisé dans la Procedure Division (dans certain ordre d’entrée-sortie)
e. Exemples de nom-fichier.
Dans le problème traité au chapitre III, trois fichiers sont nécessaires, le fichier principal, le fichier optionnel et le fichier facturation.
On peut leur donner les noms respectifs suivants :
pour le fichier principal;
pour le fichier optionnel; OPTIØNNEL
pour le fichier facturation.
GENERALITE COBOL/ NOM-HARDWARE OU NOM-UNITE
a.Définition.
Le nom-hardware est un nom-donnée qui sert ã identifier un équipement périphérique, ou une partie d’équipement périphérique (disque magnétique). I1 sert de lien entre le programme COBOL et le système.
b. Formation et écriture.
Les règles varient avec chaque constructeur, car ce nom doit suivre les règles propres ã chaque système d’exploitation. Chez certains :constructeurs, il existe pour le nom-hardware, des mots réservés ayant ne signification particulière.
Chez CDC de la série des 6000
Le nom-hardware a de 1 à 7 caractères alphanumériques et le 1er doit être alphabétique. S’il est formé de plus de 7 caractères, seuls les 7 premiers sont pris en compte. Des mots réservés existent
INPUT : désignant le fichier standard d’entrée (lecteur de carte)
Output : désignantle fichier standard de sortie (imprimante)
Punch : désignant Le fichier de la perforation ( caractères Hollerith)
PunchB : désignant le fichier de perforation ( caractères binaires)
Chez IBM de la série des 360
Le nom-hardware a de 1 à 8 caractères alphanumériques et le 1er doit être alphabétique. Il doit être mis entre guillemets ou apostrophes.
Chez UNIVAC de la série 1108
Il n’existe chez ce constructeur que des mots réservés.
CARD-READER-EIGHTY : désignant le fichier standard d’entrée
CARD-PUNCH-EIGHTY
MASS-STORAGE
PRINTER
UNISERVØ
(lecteur de cartes);
: désignant le fichier standard de sortie (perforateur de cartes);
: désignant 1’unité de disque magnétique;
:désignant 1’imprimante;
: désignant l’unité de bande magnétique.
Chez CII de la série des IRIS 50
De plus, il existe des mots réservés :
SYSIN
SYSØUT
: désignant le fichier standard d’entrée (1ecteur de cartes);
: désignant le fichier standard de sortie (imprimante);
SYSPUNCH : désignant le fichier standard de sortie (perforateur de cartes)
Chez HONEYWELL BULL de la série GE 600.
Le non-hardware a 2 caractères alphanumériques, le premier étant obligatoirement alphabétique.
De plus, si 1’unité d’entrée considérée est le lecteur de carte le nom-hardware doit être suivi des mots réservés FØR CARDS.
Si l’unité de sortie considérée est 1’imprimante le nom-hardware doit être suivi des mots réservés FØR LISTING.
Partie du programme où il est défini.
I1 est défini, (lorsque ce n’est pas un mot réservé) dans 1’Environment Division et on le retrouve dans les cartes de contrôle nécessaires ã 1’exécution du programme.
Partie du programme où il est utilisé.
C’est son utilisation qui le définit dans 1’Environment Division
Exemples de noms-hardware.
CDC :INPUT
TAPE01
SØRTIES
IBM
GENERALITES COBOL
101
:’SY020′
‘SØRTIES’
‘TAPE0123’
UNIVAC:CARD-READER-EIGHTY
PRINTER
NOM-BIBLIOTHEQUE
Souvent dans un programme, il est nécessaire d’écrire des séquences fichiers dans la Data Division de P2 doit être identiques à celles décrites dans d’autres programme P1. Il est parfois nécessaire que la description des fichiers dans la Data Division P2 soit identique à celle de la Data Division de P1. De même une ou plusieurs séquences d’instructions de l’Environnent Division, ou de la Procedure Division e P1 peuvent être nécessaires dans P2.. Afin d’éviter au programmer la réécriture de ces séquences sur un fichier spécial du système appele « fichier librairie » et de les faire insérer dans P2, a partir de ce fichier librairie lors de la compilation de P2. I1 suffit pour cela, d’avoir affecté à chacune de ces séquences un nom, appelé nom-bibliothêque.
Un nom-bibliothèque est donc le nom d’une des séquences du fichier librairie que 1’on peut insérer dans un programme quelconque en 1’appelant, de ce programme, par son nom.
Formation et écriture.
Le nom-bibliothèque obéit aux mêmes règles que celles du nom-don-née.
Partie du programme oũ il est défini.
« Le fichier librairie » contenant donc les différents noms-bibliothèque
et les séquences de programme correspondantes, est une annexe du compilateur COBOL. Sa création doit être antérieure ã la compilation du programme COBOL qui y fera appel. De ce fait, le nom-bibliothèque n’est pas défini dans un programme COBOL mais au moment de la création du « fichier librairie » propre ã 1’ordinateur.